Reference-Based Sketch Image Colorization
using Augmented-Self Reference and Dense Semantic Correspondence
CVPR 2020

Abstract
This paper tackles the automatic colorization task of a sketch image given an already-colored reference image. Colorizing a sketch image is in high demand in comics, animation, and other content creation applications, but it suffers from information scarcity of a sketch image. To address this, a reference image can render the colorization process in a reliable and user-driven manner. However, it is difficult to prepare for a training data set that has a sufficient amount of semantically meaningful pairs of images as well as the ground truth for a colored image reflecting a given reference (e.g., coloring a sketch of an originally blue car given a reference green car). To tackle this challenge, we propose to utilize the identical image with geometric distortion as a virtual reference, which makes it possible to secure the ground truth for a colored output image. Furthermore, it naturally provides the ground truth for dense semantic correspondence, which we utilize in our internal attention mechanism for color transfer from reference to sketch input. We demonstrate the effectiveness of our approach in various types of sketch image colorization via quantitative as well as qualitative evaluation against existing methods.
Paper and Supplementary Material

Method overview
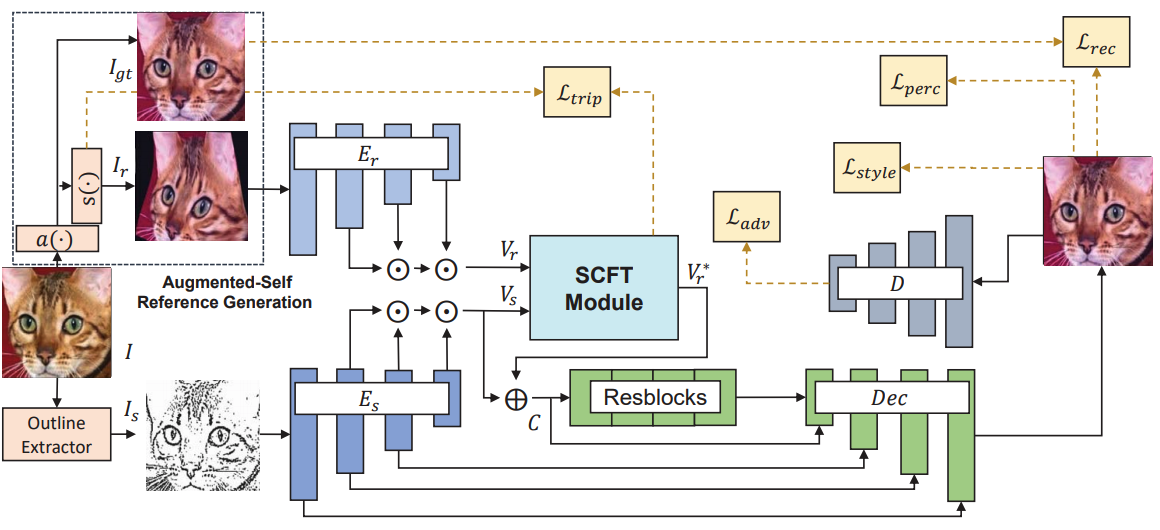
As illustrated in Figure 2, given a color image in our dataset, we first convert it into its sketch image using an outline extractor. Additionally, we generate an augmented-self reference image by applying the spaital transformation and color jittering. By this method, we can obtain the reference image that contains enough semantics of objects of the original while preventing the model from learning trivial copy operation. Afterwards, our model creates a colored image by using features which are transfered from the refernce encoder (Figure 3).
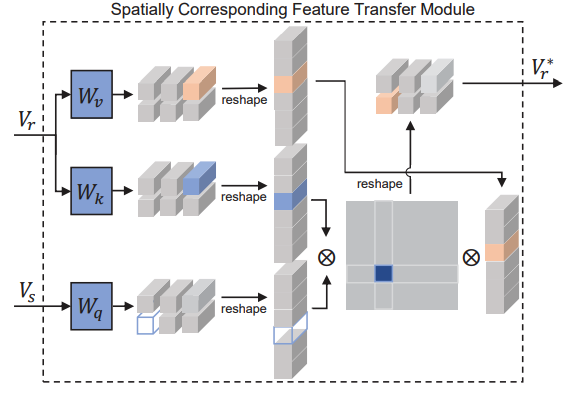
In order to transfer the information from the reference to the source image, we present a SCFT module inspired by a recently proposed self-attention mechanism, which computes dense correspondneces between every pixel pair of reference to source image. The goal of this module is to learn (1) which part of a refernce image to bring the information from as well as (2) which part of a sketch image to transfer such information to, i.e., transferring the information from where to where. Once obtaining this information as an attention map, our model transfers the feature information from a particular region of a reference to its semantically corresponding pixel of the given sketch. Based on these visual mappings obtained from SCFT, context features fusing the information between the reference and the source passes through several residual blocks and U-net-based decoder sequentially to generate the final colored output.
Additional Results



Citation
@InProceedings{Lee_2020_CVPR,author = {Lee, Junsoo and Kim, Eungyeup and Lee, Yunsung and Kim, Dongjun and Chang, Jaehyuk and Choo, Jaegul},
title = {Reference-Based Sketch Image Colorization Using Augmented-Self Reference and Dense Semantic Correspondence},
booktitle = {The IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2020}}