
Generative AI · Research & Serving
Junsoo Lee
AI Research Scientist — Generative Modeling & Software Engineering
NAVER WEBTOON AI · M.S. in AI, KAIST
Seongnam, Republic of Korea
“Do it, like a Pro.”
AI Research Scientist — Generative Modeling & Software Engineering
NAVER WEBTOON AI · M.S. in AI, KAIST
Seongnam, Republic of Korea
“Do it, like a Pro.”
AI Researcher & Engineer at NAVER WEBTOON, with an M.S. in AI from KAIST (advised by Prof. Jaegul Choo). I bridge the gap between research and production — designing AI systems from paper to deployment.
Over 4+ years I've built a unified AI platform serving generative models, designed multi-agent architectures, trained video foundation models, and shipped character generation to live consumer services. I've published at top-tier venues (AAAI, ECCV, ICCV, ACM MM), filed 3 patents, and reviewed 20+ papers in diffusion models, video generation and multimodal learning.
My current interests lie at the intersection of Robotics AI, Agentic AI, Generative Foundation Models, and Finance — building autonomous, intelligent systems that reason, act, and create value in the real world. I thrive in roles that demand both rigorous research thinking and hands-on engineering execution.
Highlights from NAVER WEBTOON AI (2021–present) — across content generation and content understanding, from research to production serving.
A unified platform for multi-model GPU serving, backend, RAG and auth — infrastructure to product APIs. An AI onboarding agent turns a model repo into a deployable service, driving the marginal cost of adding a model toward zero.
End-to-end, anime-domain video generation on a "data is the model" premise — multi-stage DiT training over a reusable, large-scale curation engine (dedup, captioning, motion & aesthetic scoring) plus Blender-based 3D data generation.
An LLM reads full web-novels and extracts characters, relationships, events, narrative and worldview into structured metadata — evolved from Hierarchical RAG (RAPTOR) to an LLM-Wiki multi-agent design, on traceable local models with a Kafka event-driven serving pipeline.
Turns raw manuscripts into structured, machine-usable data: a production PSD engine (custom RGBA compositing) and a cascading CV pipeline (classify → segment → detect) — a platform asset feeding scroll-view, translation, animation and effect automation.
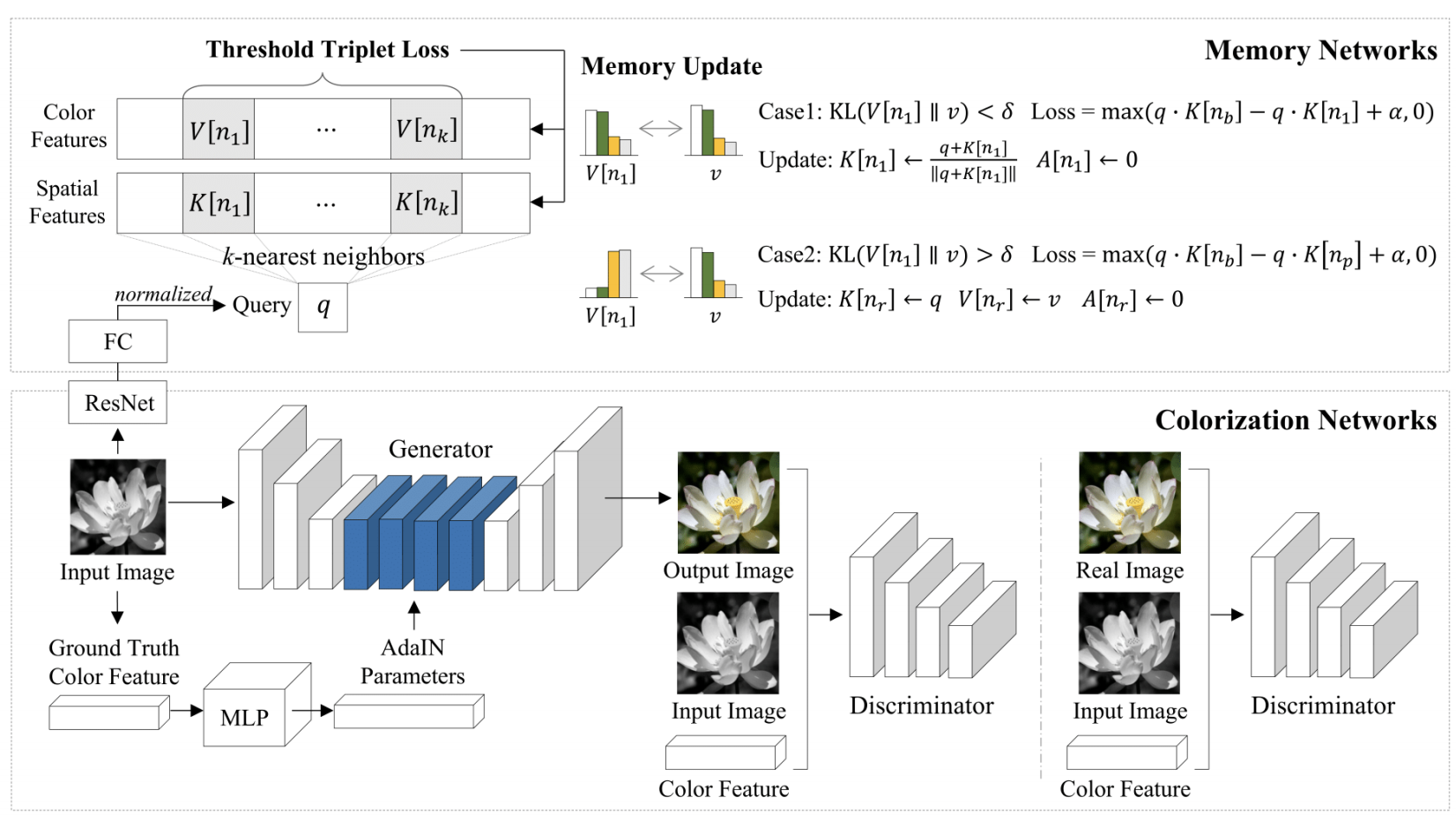
Temporally-coherent colorization for animation via reference-based visual correspondence. Novel shadow-surface propagation and self-supervised (DINO) features won over initially-skeptical studio partners.
Cascaded identity preservation (Style LoRA → IP-Adapter → FaceID) with per-character 3D pose DBs, and a text-to-video pipeline — among the org's first cases of generative AI serving end users directly.
Served and integrated audio generation across modalities — TTS with voice cloning (model-swappable for zero-downtime upgrades), text-to-music, text-to-sound and video-to-audio — all in one unified serving framework.
Research and large-scale serving across vision, video, audio and language — a full-stack multimodal generative-AI portfolio.
Among the organization's first generative-AI features to serve end users directly, in a live consumer service.
5 top-tier publications (AAAI'24, ECCV'24 ×2, ICCV'23, ACM.MM'23) and 3 patents in colorization & virtual try-on.
Platforms spanning 6+ served models, 260K+ training clips, and 1,000+ episode long-form series.
Peer-reviewed work at top-tier venues. * denotes equal contribution. Full list on Google Scholar.




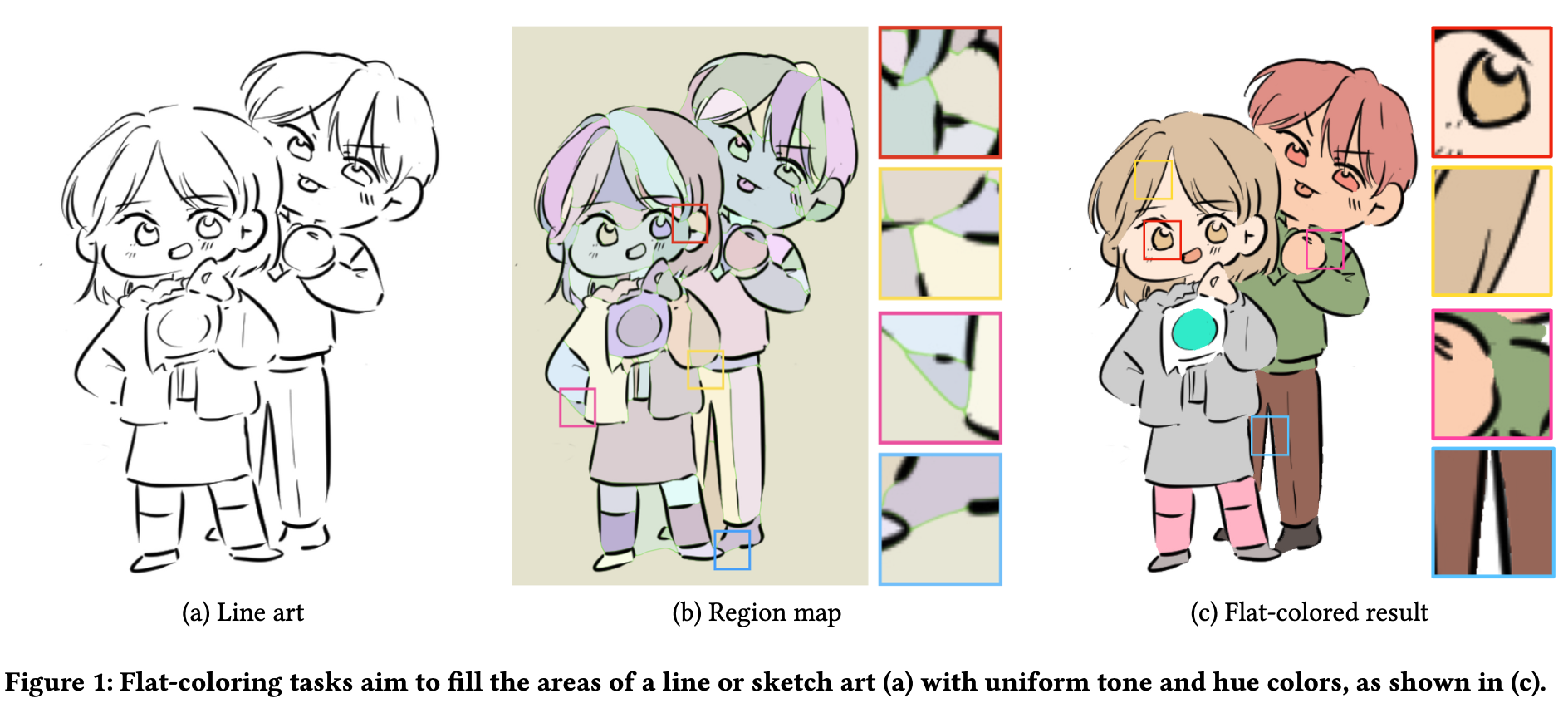
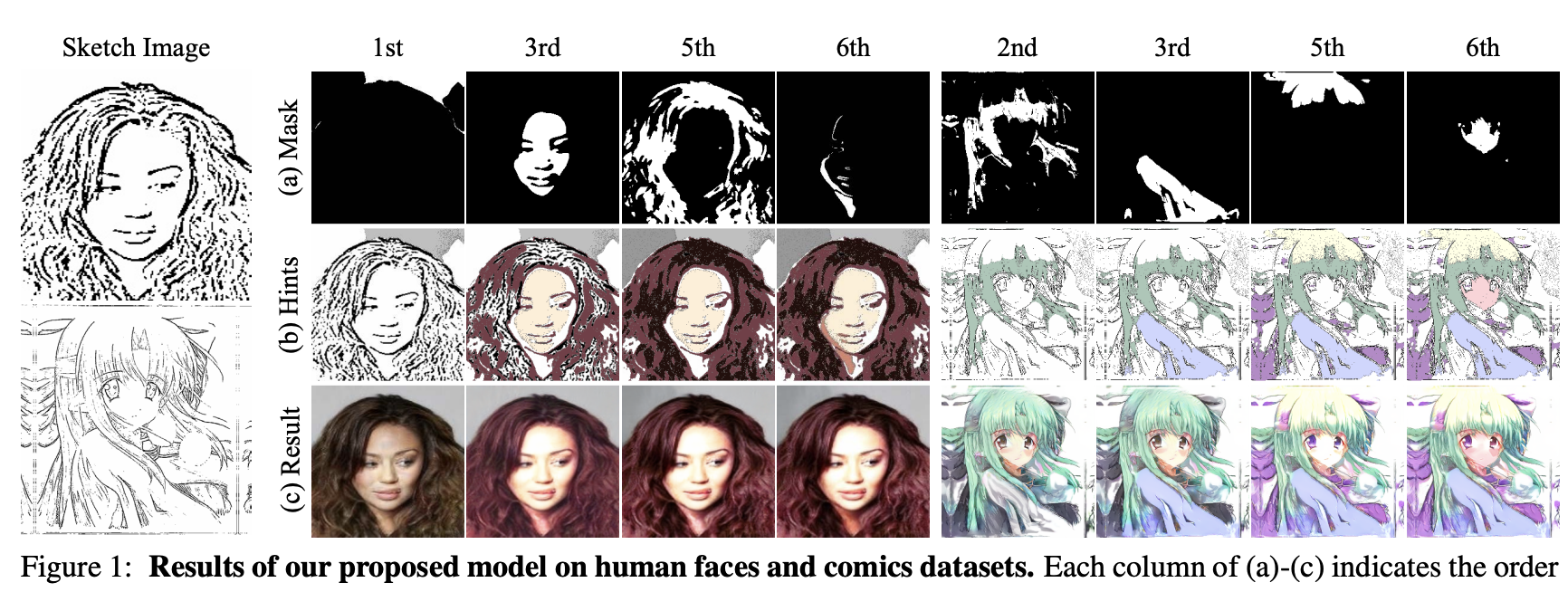
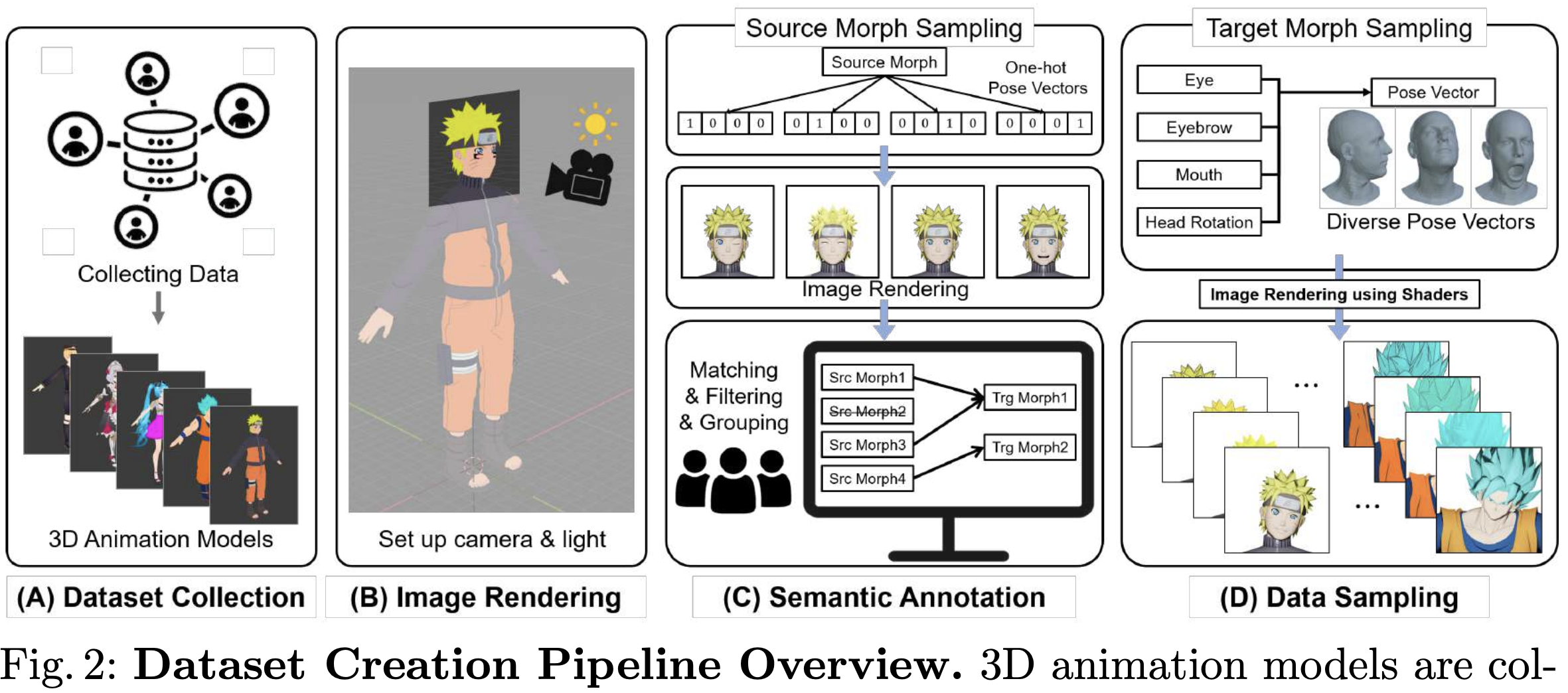
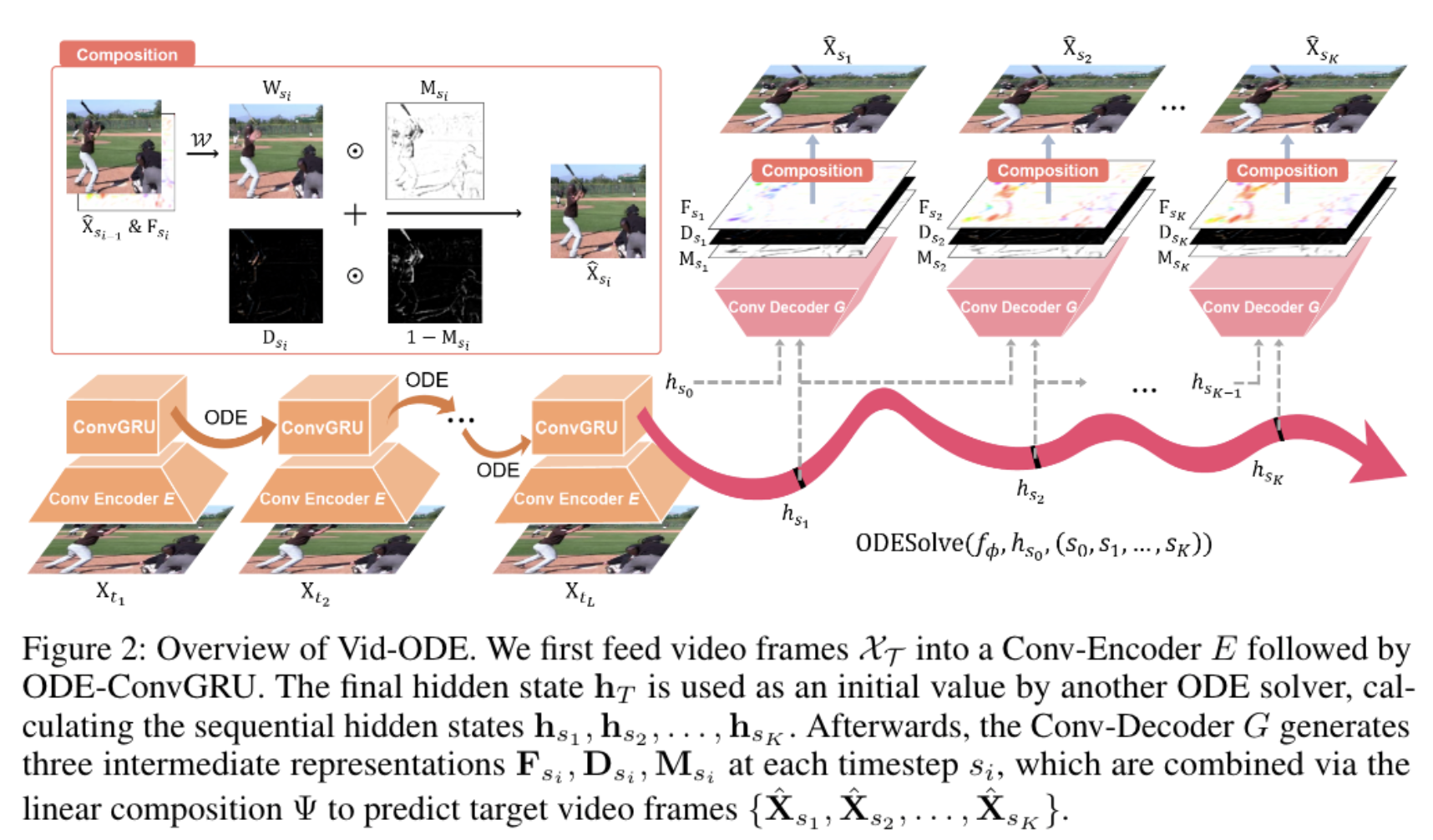

Also: DiffBlender, LPMM (CVPRW'23), Reference-based Image Composition (CVPRW'23), Decomposing Image Animation Identity, C2BIN, and Understanding Human-side Impact of Image Sequencing (CSCW'21) — see Scholar for the complete list.